The ScyllaDB team is pleased to announce the release of ScyllaDB Open Source 5.1, a production-ready release of our open-source NoSQL database.
ScyllaDB 5.1 introduces Partition level rate limit, Distributed select count, and more functional, performance and stability improvements.
Only the last two minor releases of the ScyllaDB Open Source project are supported. As ScyllaDB Open Source 5.1 is officially released, only ScyllaDB Open Source 5.1 and ScyllaDB 5.0 will be supported; ScyllaDB 4.6 will be retired. Users are encouraged to upgrade to the latest and greatest release. Upgrade instructions are here.
Related Links
-
Get ScyllaDB Open Source 5.1 as binary packages (RPM/DEB), AWS AMI, GCP Image and Docker image
New Features
Distributed SELECT COUNT(*)
ScyllaDB will now automatically run SELECT COUNT(*) statements on all nodes and all shards in parallel, which brings a considerable speedup, even 100X in larger clusters.
This feature is limited to queries that do not use GROUP BY or filtering.
The implementation includes a new level of coordination.
A Super-Coordinator node splits aggregation queries into sub-queries, distributes them across some group of coordinators, and merges results.
Like a regular coordinator, the Super-Coordinator is a per operation function.
Example results:
A 3 node cluster setup on powerful desktops (3x32 vCPU)
Filled the cluster with ~2 * 10^8 rows using scylla-bench and run:
time cqlsh --request-timeout=3600 -e “select count(*) from scylla_bench.test using timeout 1h;”
Before Distributed Select: 68s
After Distributed Select: 2s
You can disable this feature by setting enable_parallelized_aggregation config parameter to false.
Limit partition access rate
It is now possible to limit read rates and writes rates into a partition with a new WITH per_partition_rate_limit clause for the CREATE TABLE and ALTER TABLE statements. This is useful to prevent hot-partition problems when high rate reads or writes are bogus (for example, arriving from spam bots). #4703
Examples:
Limits are configured separately for reads and writes. Some examples:
ALTER TABLE t WITH per_partition_rate_limit = {
‘max_reads_per_second’: 100,
‘max_writes_per_second’: 200
};
Limit reads only, no limit for writes:
ALTER TABLE t WITH per_partition_rate_limit = {
‘max_reads_per_second’: 200
};
Load and stream
This feature extends nodetool refresh to allow loading arbitrary sstables that do not belong to a particular node into the cluster. It loads the sstables from disk, calculates the data’s owning nodes, and automatically streams the data to the owning nodes. In particular this is useful when restoring a cluster from backup.
For example, say the old cluster has 6 nodes and the new cluster has 3 nodes.
One can copy the sstables from the old cluster to the new nodes and trigger the load and stream process.
This can make restores and migrations much easier:
- You can place sstables from any node from the old cluster to any node in the new cluster
- No need to run nodetool cleanup to remove data that does not belong to the local node after refresh
Load_and_stream option also updates the relevant Materialized Views #9205
curl -X POST "http://{ip}:10000/storage_service/sstables/{keyspace}?cf={table}&load_and_stream=true
Note there is an open bug, #282 , for the Nodetool refresh --load-and-stream operation. Until it is fixed, use the REST API above.
Materialized Views: Prune
A new CQL extension PRUNE MATERIALIZED VIEW statement can now be used to remove inconsistent rows from materialized views. A special statement is dedicated for pruning ghost rows from materialized views.
A ghost row is an inconsistency issue which manifests itself by having rows in a materialized view which do not correspond to any base table rows. Such inconsistencies should be prevented altogether and ScyllaDB strives to avoid them, but if they happen, this statement can be used to restore a materialized view
to a fully consistent state without rebuilding it from scratch.
Example usages:
PRUNE MATERIALIZED VIEW my_view;
PRUNE MATERIALIZED VIEW my_view WHERE token(v) > 7 AND token(v) < 1535250;
PRUNE MATERIALIZED VIEW my_view WHERE v = 19;
Alternator updates
Alternator, ScyllaDB’s implementation of the DynamoDB API, now provides the following improvements:
- Supports partially successful batch queries where successful results are returned and failed keys are reported. #9984
- Uses Raft (if enabled) to make table creation atomic. #9868
- Alternator will BYPASS CACHE for the scans employed in TTL expiration, reducing impact on user workloads.
- New metrics that can be used to understand alternator TTL expiration operation.
- Supports Select option of Query and Scan methods. This allows counting items instead of just returning them.#5058
- An improvement to BatchGetItem performance by grouping requests to the same partition.#10757
Materialized Views: Synchronous Mode - Experimental
There is now a synchronous mode for materialized views. In ordinary, asynchronous mode materialized views operations return before the view is updated. In synchronous mode materialized views operations do not return until the view is updated. This enhances consistency but reduces availability as in some situations all nodes might be required to be functional.
Example:
CREATE MATERIALIZED VIEW main.mv
AS SELECT * FROM main.t
wHERE v IS NOT NULL
PRIMARY KEY (v, id)
WITH synchronous_updates = true;
ALTER MATERIALIZED VIEW main.mv WITH synchronous_updates = true;
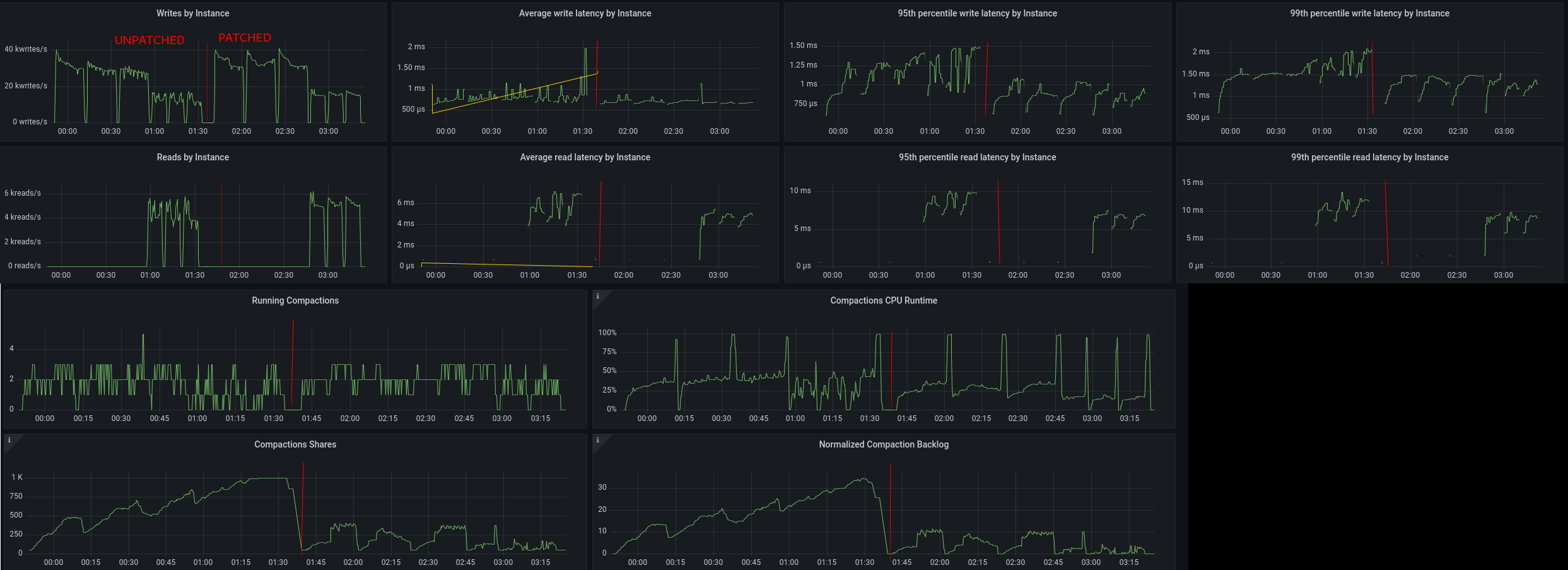
Performance: Eliminate exceptions from the read and write path
When a coordinator times out, it generates an exception which is then caught in a higher layer and converted to a protocol message. Since exceptions are slow, this can make a node that experiences timeouts become even slower. To prevent that, the coordinator write path and read path has been converted not to use exceptions for timeout cases, treating them as another kind of result value instead. Further work on the read path and on the replica reduces the cost of timeouts, so that goodput is preserved while a node is overloaded.
Improvement results below

Raft Updates
While strong consistent schema management remains experimental in 5.1, the work on the Raft consensus algorithm continues toward more use cases, such as safe topology updates, improving traceability and stability. Here are selected updates in this release:
- A Data Definition Language (DDL) statement will fail under Raft-managed schema if a concurrent change is applied. ScyllaDB will now automatically retry executing the statement, and if there was no conflict between the two concurrently executing statements (for example, if they apply to different tables) it will succeed. This reduces disruption to user workloads.
- ScyllaDB will retry a DDL statement if a transient Raft failure has occurred, e.g. due to a leader change.
- When Raft is enabled, nodes join as non-voting members until bootstrap is complete.
- When node A sends a read or write request to node B, it will also send the schema version of the relevant table. If B is using a different version, it will ask A for the schema corresponding to that version. If A doesn’t have it, the request will fail. Consequently the cache expiration for schema versions has been increased to reduce the probability of such events.
- Raft now persists its peer nodes in a local table.
- The system could deadlock if a schema-modifying statement was executed in Raft mode during shutdown. This is now fixed.
- A new failure detector was merged for Raft.
- There is a new test suite for testing topology changes under Raft.
Web Assembly (WASM) based UDA/UDF - Experimental
ScyllaDB 5.1 brings experimental support for Wasm-based User Defined Functions (UDFs) and User Defined Aggregates (UDAs).
The CQL syntax is compatible with Apache Cassandra. Examples:
CREATE FUNCTION sample ( arg int ) …;
CREATE FUNCTION sample ( arg text ) …;
A full example of using Rust to create a UDF will be shared soon.
To enable WASM UDF in ScyllaDB 5.1:
Use options
–enable-user-defined-functions true --experimental-features udf
Or in scylla.yaml:
experimental_features:
- udf
Issues fixed in this release:
- Memory management for User Defined Functions (UDF) in WebAssembly has been significantly improved. There is now a protocol that allows ScyllaDB to allocate memory within the function’s memory space to store function parameters. This means that within a WebAssembly function, normal memory management can be used (e.g. Rust’s “new” methods).
- in WebAssembly UDF, the RETURNS NULL ON NULL INPUT is now honored.
- User-defined aggregates can now have a REDUCEFUNC defined, allowing them to run in parallel on all shards and nodes. In addition, all native aggregates can now be parallelized (not just COUNT(*)), and multiple aggregations in a single SELECT statement are supported.
- A compiled WebAssembly function will now be reused across multiple invocations. Creating a WebAssembly function instance is very expensive, so we amortize the creation across many invocations.
More update in Part 2 below!
{kind=link}