Installation details
#ScyllaDB version: 5.0.5-0.20221009
#Cluster size: 6 nodes (3 - us-east-1; 3 - us-east-2) Replication factor 3
os (debian10-base-amd64-202408061511):
Hello!
We randomly have ScyllaDB load/latency spikes in some nodes every day shortly after 00h00 UTC. This lasts for about 30 seconds, in each node, and during that period, all the queries to node time out, it looks like that node is not available.
In the metrics of the EC2 instance, we see this load spike:
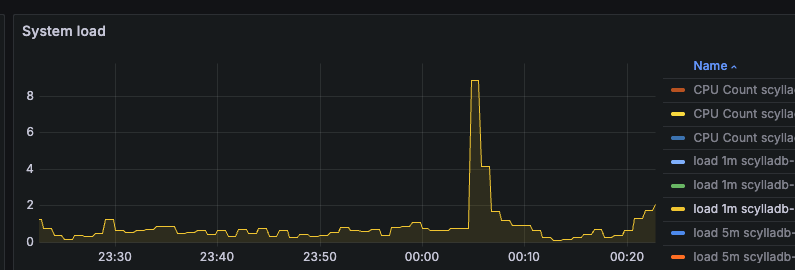
The compactions are running during the day and nothing out of normal is running at this time. We also don’t have a spike in throughput, in fact is decreasing at this time of the day. We don’t have any scheduled jobs, backup, repair, etc, scheduled for this time frame.
Do you have any idea why this might be occurring? We are running out of ideas…
Thank you!