See Part 1
More Improvements
CQL API
- CQL Conflict resolution: compare_cells_for_merge may wrongly prefer an expired cell over a live and expiring one #14182. Before this fix, when two cells have the same write timestamp and both are alive or expiring, we compare their value first, before checking if either of them is expiring and if both are expiring, comparing their expiration time and TTL value to determine which of them will expire later or was written later. This was based on an early version of Cassandra. However, the Cassandra implementation rightfully changed in CASSANDRA-14592, where the cell expiration is considered before the cell value. See update-ordering in Scylla docs for more.
- REST API: Allow tombstone GC in compaction to be disabled on user request #14077
The fix adds new APIs /column_family/tombstone_gc and /storage_service/tombstone_gc, that will allow for disabling tombstone garbage collection (GC) in compaction.
-
Get status: curl -s -X GET “http://127.0.0.1:10000/column_family/tombstone_gc/ks:cf”
-
Enable GC curl -s -X POST “http://127.0.0.1:10000/column_family/tombstone_gc/ks:cf”
-
Disable GC curl -s -X DELETE “http://127.0.0.1:10000/column_family/tombstone_gc/ks:cf”
-
ScyllaDB now supports server-side DESCRIBE. This is required for the latest cqlsh, and reduces the need to update cqlsh as server features are added. However, the version number bump needed to inform cqlsh about this change was reverted as other changes related to the version number are not ready.
-
The CQL binary protocol versions 1 and 2 are no longer supported. Version 3 and above have been supported for 9 years, so it’s unlikely to be in real use. You can check for version 1 and 2 in the system.clients virtual table. #10607
-
There is now documentation about how NULL is treated in ScyllaDB. #12494
-
USING TIMESTAMP allows setting the mutation timestamp on a CQL statement level. It has a sanity check that prevents setting timestamps in the future, as these can be hard to delete, but sometimes one wishes to do so anyway. There is now a configuration option that allows disabling the feature. #12527
-
TRUNCATE statements are usually much slower than other statements. TRUNCATE statements now support the WITH TIMEOUT clause to help deal with that. #11408
-
The CQL CONTAINS and CONTAINS KEY operators are used to check if a collection contains an element. CONTAINS and CONTAINS KEY have been changed to return false if it is asked whether a collection contains NULL, since no collection can contain a NULL. This is a behavior change, but is not expected to affect users since the query is not useful. #10359
-
In the expression element IN list, we now allow “list” to be NULL (and the expression evaluates to false). Previously, this failed with an error.
-
A regression where CQL ignored some WHERE clause components when a multi-column restriction ((col_a, col_b) < (0, 0)) was present was fixed. #6200 #12014
-
In SELECT JSON statements, column names can be given aliases (just as with traditional SELECT). However, ScyllaDB ignored those aliases. It will now honor them. #8078
-
Evaluation of Boolean binary operators (e.g. “=”) has been refactored to use the same expression evaluation code as other expressions, paving the way for relaxation of the CQL grammar to be more similar to SQL.
-
The experimental User-defined aggregates (UDAs) have a state type that can be initialized using the INITCOND clause. The initializer can now be a collection type.
-
CQL: scylla: types: is_tuple(): doesn’t handle reverse types. For example, a schema with reversed clustering key component; this component will be incorrectly represented in the schema CQL dump: the UDT will lose the frozen attribute. When attempting to recreate this schema based on the dump, it will fail as the only frozen UDTs are allowed in primary key components.
#12576 (RC1)
- Integer columns now accept scientific notation JSON numbers, as long as those numbers are integers. This improves interoperability with JSON libraries (and fixes a regression). Fixes #10100 #10114 #10115
- Empty strings are now allowed in materialized view partition keys. #9352 #9364 #9375
-
The LIKE operator on descending order clustering keys now works. #10183
-
ScyllaDB would incorrectly use an index with some IN queries, leading to incorrect results. This is now fixed.
-
In CREATE AGGREGATE statements, the INITCOND and FINALFUNC clauses are now optional (defaulting to NULL and the identity function respectively).
-
CREATE KEYSPACE now has a WITH STORAGE clause, allowing to customize where data is stored. For now, this is only a placeholder for future extensions.
-
When talking to drivers using the older v3 protocol, ScyllaDB did not serialize timeout exceptions correctly, resulting in the driver complaining about protocol violations. This is now fixed. #5610
-
The CQL grammar was relaxed to allow bind markers in collection literals, e.g. UPDATE tab SET my_set = { ?, ‘foobar’, :variable }.
-
ScyllaDB now validates collections for NULLs more carefully. #10580
After this change, the following query
INSERT INTO ks.t (list_column) VALUES (?);
And the driver sending a list with null inside as the bound value, something like [1, 2, null, 4] Would result in an invalid_request_exception instead of an ugly marshaling error.
- Support for lists containing NULLs in IN relations (“WHERE x IN (1, 2, NULL, 3)”) has been removed. This is useless (since NULL doesn’t match anything) and conflicts with how lists work elsewhere.
- WHERE clause processing has been relaxed to allow filtering on a list element: “WHERE my_list[:index] = :value ALLOW FILTERING”. Previously this was only allowed on maps.
- Lightweight transaction behavior wrt static rows was adjusted to conform to Cassandra’s behavior.
- If a named bind variable appeared twice in a statement (“WHERE a = :my_var AND b = :my_var”), ScyllaDB treated this as two separate variables. This is now fixed. #10810
- The token() built-in function will now correctly return NULL if given NULL inputs, instead of failing the request. #10594
- CQL: Scylla sum function (and other aggregates function) fails when used with case-sensitive column names. #14307
Amazon DynamoDB Compatible API (Alternator)
Alternator, ScyllaDB’s implementation of the DynamoDB API, now provides the following improvements:
- Alternator will now associate service level information configured via the CQL ATTACH SERVICE LEVEL statement with the authenticated alternator user.
- Bug fix: UpdateItem setting the same value again for GSI range key may drop the row #11801
- Alternator has better validation of malformed base64 encoded values. #6487
- Alternator now sets the Projection field in response to the DescribeTable request.
- A bug in alternator WHERE condition for global secondary index range key, that does not appear to have any user visible impact, has been fixed.
- Alternator implements Time-To-Live (TTL) by scanning data. Some shutdown-related hangs in the scanning process were fixed.
- Alternator, uses the rapidjson library to parse queries presented as JSON. Due to a compile-time misconfiguration, aggressive inlining was not enabled. This is now fixed, yielding a substantial 5 performance improvement.
- A Seastar update fixed an ambiguity in the http parser, which caused Alternator requests to be unnecessarily slow. 12468
- Alternator Streaming API: unexpected ARN values by list streams paged responses. This issue may only affect users with many, more than 100, tables with streams #12601
- Supports partially successful batch queries where successful results are returned and failed keys are reported. #9984
- Uses Raft (if enabled) to make table creation atomic. #9868
- Alternator will BYPASS CACHE for the scans employed in TTL expiration, reducing impact on user workloads.
- New metrics that can be used to understand alternator TTL expiration operation.
- Supports Select option of Query and Scan methods. This allows counting items instead of just returning them.#5058
- An improvement to BatchGetItem performance by grouping requests to the same partition.#10757
Correctness
- ScyllaDB represents reads using mutation fragment streams. Several minor violations of fragment stream integrity were fixed. These could result in incorrect reads during range scans. #12735
- The view builder is responsible for building materialized views when a view is created and after repair. To control its memory consumption, it reads base table sstables in chunks. Due to a bug, it could forget the partition tombstone or an open range tombstone when moving between chunks, leading to a discrepancy between the base table data and the view data. This is now fixed. #11668
- When a table with a materialized view had a large partition, and that large partition was deleted with the USING TIMESTAMP clause, the materialized view might be only partially updated. This is now fixed. #12297.
- The row cache could have missed reading a row if a row is evicted concurrently while being read, plus other conditions. This is now fixed. #11239
Performance and stability
- TRUNCATE statements are usually much slower than other statements. TRUNCATE statements now support the WITH TIMEOUT clause to help deal with that. #11408
- ScyllaDB uses an interval map data structure from the Boost library to quickly locate sstables needed to service a read. Due to the way we interface with the library, updating the interval map was unnecessarily slow. This is now fixed. #11669
- Materialized view building will now ignore partitions no longer owned by the node after a topology change.
- When a materialized view processes updates to the base table, it locks the partition and clustering key. In some rare cases involving one of the locks timing out but the other not, this can cause a crash. This was fixed by acquiring the locks sequentially. #12168
- The experimental WASM user defined function (UDF) implementation has been switched to Rust (UDFs can be written in any language WASM supports, not just Rust). The new implementation avoids stalls for long-running UDFs and shares memory with the rest of the database. #11351
- The experimental WASM user defined function (UDF) has been re-enabled for aarch64 (ARM).
- User defined aggregates (UDAs) are now correctly persisted and survive a cold start. UDAs are an experimental feature. #11309
- A bug that caused user-defined aggregates not to be persisted correctly was fixed. #11327
- A very rare bug involving reads from memtables and multi-version concurrency control has been fixed.
- Automatically parallelized query aggregation, introduced in 5.1, used a node-local clock for timeouts, rather than the standard clock. This meant that automatically parallelized queries would fail, unless the nodes were started at the same time. This is now fixed. #12458
- During startup, ScyllaDB makes sstables conform to the compaction strategy in a process called reshaping, so that future reads will perform well. It is now more careful when reshaping Leveled Compaction Strategy tables, to avoid doing unnecessary work. #12495.
- Lightweight transactions are now more robust when the schema is changed during a transaction. #10770
- A very rare bug involving reads from memtables and multi-version concurrency control has been fixed.
- Single-partition reads could, in conditions involving multi-page queries, a completely empty page, and a partition or range tombstone covering the first row, terminate paging prematurely, leading to incorrect results. This is now fixed. #12361
- Everywhere replication strategy exhibited quadratic behavior since each vNode has every node in its replica set. Since the number of vNodes is proportional to the number of nodes, the amount of work grows quadratically, slowing down topology operations on large clusters. We now special-case this path to avoid the problem. #10337
- When using the EverywhereReplicationStrategy, vnodes have no impact on data distribution, and so we can avoid splitting the query across vnodes. This improves performance on tables with a small amount of data.
- A small race between DROP TABLE and inactive reads (readers that have just completed sending a page to the coordinator and are awaiting the next page fetch) was fixed. #11264
- The internal representation of a CREATE TABLE statement now includes the equivalent of a DROP TABLE. This is normally unnecessary, since CREATE TABLE checks if the table already exists and refuses to proceed, but in the case of two CREATE TABLE statements executing concurrently on two different nodes (but creating the same table), each node’s check misses the other’s concurrently created new table. If the table definitions are different, this can lead to a cluster crash due to the mixture between the two definitions being illegal. The change ensures that the two table definitions are not intermixed and just one survives. Users are still urged not to create tables with the same name concurrently until the Raft schema management transition is complete. #11396
- Vestigial support for compaction groups has been merged. Compaction groups are token ranges that have dedicated sstables and memtables, and so can be compacted and moved independently of each other. Currently, exactly one compaction group per table is supported, so this doesn’t change anything, but it will be expanded in the future.
- The database now performs sanity tests around TimeWindowCompactionStrategy tables, to limit the number of time windows. Too many time windows can cause the system to run out of memory or open file handles. #9029
- Per partition rate limit error error reporting has been corrected to report the new error code when an updated driver is available.#11517
Support for the new error code has been merged to:
-
Scylla Rust Driver support since version 0.6.0
-
Gocq - merged to master but it’s not a part of any release.
-
Off-strategy compaction is used when sstables from an external source (such as repair) needs to be reshaped before being handed off to the table’s compaction strategy. If off-strategy compaction is stopped, ScyllaDB used to just leave those sstables in their unreshaped form without compacting them again. It will now hand off such sstables directly to the table’s compaction strategy. #11543.
-
In compaction strategies such as LeveledCompactionStrategy and ScyllaDB Enterprise’s IncrementalCompactionStrategy, sstables are sealed when they reach a certain size (160MB and 1GB respectively). They are not split in the middle of a partition, because we were not able to recover the ordering of such split sstables. This is now possible (though not yet integrated into the compaction strategies).
-
Performance: Long-term index caching in the global cache, as introduced in 4.6, hurts the performance for workloads where accesses to the index are sparse. To mitigate this, a new configuration parameter cache_index_pages (default true) is introduced to control index caching. Setting the flag to
falsecauses all index reads to behave like they would in BYPASS CACHE queries. Consider using false if you notice performance problems due to lowered cache hit ratio in 4.6 or 5.0. The config API can update the parameter live (without restart). #11202 -
Scylla will now reject a too-low bloom_fulter_fp_chance when creating (or altering) the table, rather than crash while flushing memtables. #11524.
-
ScyllaDB represents reads using mutation fragment streams. Several minor violations of fragment stream integrity were fixed. These could result in incorrect reads during range scans.
-
The log-structured allocator is used to manage cache and memtable memory. When memory runs out, the allocator tries to reclaim memory by evicting cache items and by defragmenting memory. If this takes too long, the allocator logs a stall report. Due to a bug, if the report threshold was set too low then the report is generated even if a stall did not happen, slowing down the system and flooding the logs. This is now fixed. #10981
-
The compaction manager now ignores out-of-disk-space (ENOSPC) exceptions when shutting down, so the server doesn’t crash in these scenarios.
-
An inaccuracy in the per_partition_rate_limit read metric was corrected. Tables with the per_partition_rate_limit property can throttle read and write activity on a per-partition basis. #11651
-
A large schema (with thousands of tables) could cause stalls when propagated from node to node. This is now fixed. #11574
-
A recently introduced regression caused a crash when speculative retry was enabled. This is now fixed. #11825
-
segmentation fault in cases where the base table schema change while MV schema is cached #10026, #11542
-
A crash when the compaction manager was asked to stop multiple times (for different reasons) was fixed.
-
A problem with RPC connections being needlessly dropped was fixed. #11780
-
When a query completes a page, ScyllaDB caches the query activity as an inactive read. When the client requests the next page, ScyllaDB re-activates the read and continues where it left off. A bug in this mechanism that could cause crashes has been fixed. #11923
-
A crash was fixed during an illegal lightweight transaction INSERT with NULL clustering key
-
ScyllaDB caches rows and (since 4.6) index entries in a single unified cache. It was observed that in some small-partition workloads index caching causes a performance regression, so index caching is now disabled by default. It can still be enabled for workloads that benefit from it. We plan to re-enable it when the regression is fixed. #11889
-
The topology management code is more relaxed about unknown endpoints to prevent crashes in tests that check for edge cases. This fixes a recent regression. #11870
-
Hinted handoff now checks that a node exists in topology before doing anything; this helps with a recent regression due to topology refactoring.
-
A crash while fetching repaid ids from the repair history table was fixed. #11966
-
Usually repair can compare and update the same shard in different nodes, for example shard 3 in one node is compared against shard 3 in another. When the number of shards in nodes is dissimilar, this doesn’t work and each shard compares against data from multiple shards in other nodes. This is now made more efficient by reducing sstable reader thrashing for this dissimilar shard count case. #12157
-
The algorithm for removing nodes from the token ring was corrected and made more efficient. It’s not known that this had any user impact. #12082
-
The CQL server will now only run requests that benefit from concurrency (e.g. QUERY and EXECUTE) in parallel. Configuration and authentication related requests will be serialized, reducing the chance for errors in those code paths.
-
A rare bug involving an allocation failure while updating cached rows was fixed. #12068
-
The system.truncated table holds information about truncation times of user tables. A recent regression caused it to be unreadable by cqlsh. It is now fixed. 12239
-
COMPACT STORAGE tables allow the user to only specify a prefix of a compound clustering key. Bugs relating to such partial keys and reversed rows were fixed.Note that compact storage is deprecated (see section). #12180
-
ScyllaDB now supports multiple compaction groups 1. This is not a user-visible feature for now.
-
Some copies of the lists of ranges to stream were eliminated from the decommission path, reducing latency spikes. #12332
-
When the global index cache is disabled, a local (per query) cache was used instead. When that cache was destroyed, a stall could result, generating a latency spike. This is now fixed. #12271
-
Compaction manager generally reacts to events to initiate compactions, but also has an hourly timer in case an event was missed (and for tombstone compaction, which isn’t triggered by an event). This timer is now less susceptible to stalls. #12390.
-
Repair tried to trigger off-strategy compaction even for a table that was dropped during repair, failing the entire repair. It ignores the dropped table now.
-
Off-strategy compaction is now enabled for all streaming topology operations (adding and removing nodes). Previously it was enabled only for repair-based node operations. Off-strategy compaction takes advantage of the fact that incoming sstables are non-overlapping to perform more efficient compaction that the one performed by the regular compaction strategy.
-
ScyllaDB sometimes reads ahead of the user request, in order to hide latency. In one case a read-ahead request which timed out caused errors to be emitted, even though this did not affect the query. The errors are now silenced. #12435
-
ScyllaDB tracks transient memory used by queries. However, it did not track decompressed memory buffers, which could lead to running out of memory in some complicated queries. This is now fixed.
-
“Unset” values are an obscure prepared statement feature that allows only some columns in an UPDATE or INSERT statement to be modified. It was a source of minor bugs and inconvenience in code. The feature has been refactored so it has less impact on the code and is more robust.
-
Fix a crash in Materialized View update row locking, caused by a race condition #12632 (RC1)
-
Fix a crash when reporting error on invalid CQL query involving field selection from a user-defined type #12739 (RC1)
-
If a file page was inserted into cache, but the insertion required a memory allocation, it could cause memory corruption. This is now fixed. File caching is part of scylla-4.6 index caching feature. #9915
-
A recent commitlog regression has been fixed: we might have created two commitlog segment files in parallel, confusing the queue that holds them. The problem was only present in scylla-4.6. #9896
-
When shutting down, compaction tasks that are sleeping while awaiting a retry are now aborted, so the shutdown is not delayed. #10112
-
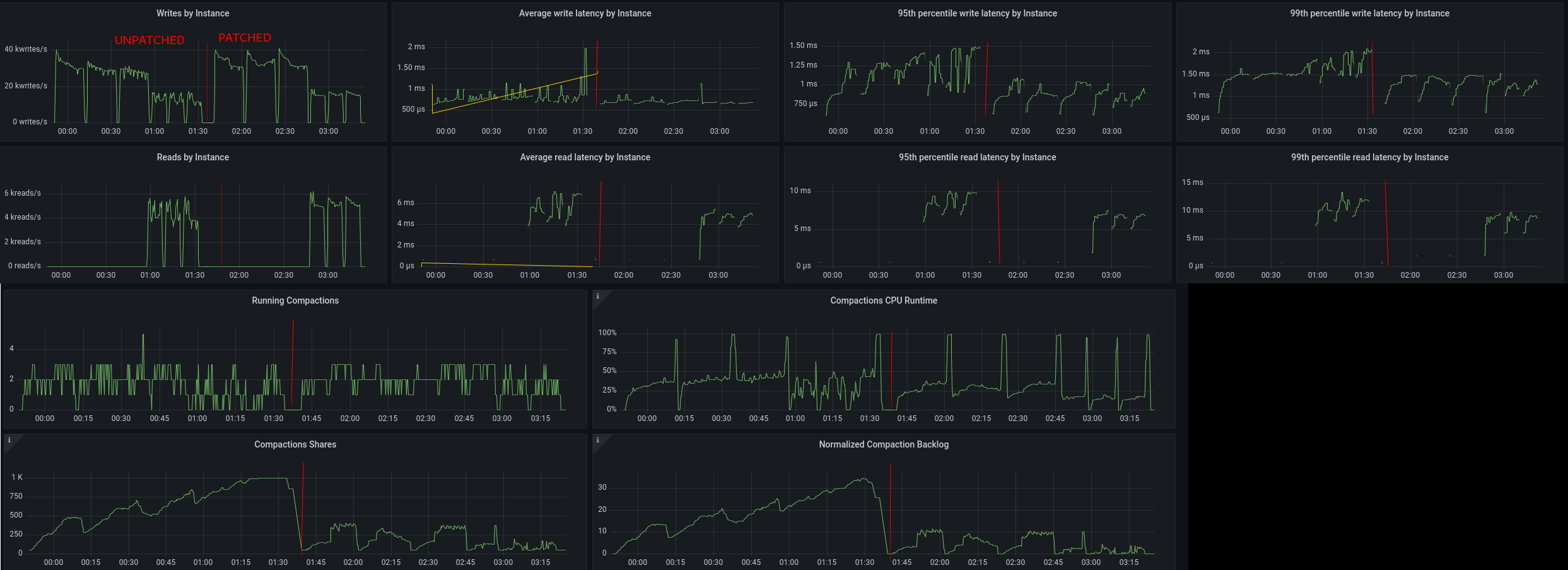
The compaction manager’s definition of compaction backlog for size-tiered compaction strategy has changed, reducing write amplification. The compaction backlog is used to determine how much resources will be devoted for compaction.
-
The compaction manager’s definition of compaction backlog for size-tiered compaction strategy has changed, reducing write amplification. The compaction backlog is used to determine how much resources will be devoted for compaction. See the results graphed here.
-
An accounting bug in sstable index caching that could lead to running out of memory has been fixed. #10056
-
ScyllaDB will shut down gracefully (without a core dump) if it encounters a permission or space problem on startup. #9573
-
sstables are created in a temporary directory to avoid serializing on an XFS lock. If the sstable writing failed, this directory would be left behind. It is now deleted. #9522
-
When using the spark migrator, ScyllaDB might see TTL’ed cells which it thought needed repair, but could not actually find a difference in, leading to repair not resolving the difference and detecting it again on the next run. This has been fixed. #10156
-
Prepared batch statements are now correctly invalidated when a referenced table changes. #10129
-
A race in the prepared statement cache could cause invalidations (due to a schema change) to be ignored. This is now fixed. #10117
-
When populating the row cache with data from sstables, we will first compact the data in order to avoid populating the cache with data that will be later ignored. #3568
-
When reading, we now notice if data exists in sstables/cache but not in memtables, or vice-versa. In either case there is no need to perform a merge, yielding substantial performance improvements.
-
Truncate now disables compaction temporarily on the table and its materialized views, in order to complete faster.
-
Cleanup compactions, used after bootstrapping a new node to reclaim space in the original nodes, now have reduced write amplification.
-
SSTable index file reads now use read-ahead. This improves performance in workloads that frequently skip over small parts of the partition (e.g. full scans with clustering key restrictions).
-
When ScyllaDB generates a name for a secondary index, it will avoid using special characters (if they were present in the table name). #3403
-
Cleanup compactions, used to discard data that was moved to a new node, now have reduced write amplification on Time Window Compaction Strategy tables
-
Reads from cache are now upgraded to use the new range tombstone representation. This completes the conversion of the read pipeline, and nets a nice performance improvement as detailed in the commit message.
-
A concurrent DROP TABLE while streaming data to another node is now tolerated. Previously, streaming would fail, requiring a restart of the node add or decommission operation. #10395
-
A crash where a map subscript was NULL in certain CQL expressions was fixed. Fixes #10361 #10399 #10401
-
A regression that prevented partially-written sstables from being deleted was fixed.
-
A race condition that allowed queries to be processed after a table was dropped (causing a crash) was fixed. #10450
-
The prepared statement cache was recently split into two sections, one for reused statements and one for single-use statements. This was done for flood protection - so that a bunch of single-use statements won’t evict reused statements from the cache. However, this created a regression when the size of the single-use section was shrunk so that it was too small for statements to promote into the reused section. This is now fixed by maintaining a minimum size for each section. #10440
-
Level selection for Leveled Compaction Strategy was improved, reducing write amplification.
-
Reconciliation is the process that happens when two replicas return non-identical results for a query. Some reactor stalls were removed, reducing latency effects on concurrent queries. #2361 #10038
-
A crash in some cases where an sstable index cursor was at the end of the file was fixed.#10403
-
A compaction job that is waiting in queue is now aborted immediately, rather than waiting to start and then getting aborted.
-
Repair-based node operations use repair to move data between nodes for bootstrap/decommission and similar operations (currently enabled by default only for replacenode). The iteration order has been changed from an outer iteration on vnodes and an inner iteration on tables to an outer iteration on tables and an inner iteration on vnodes, allowing tables to be completed earlier. This in turn allows compaction to reduce the number of sstables earlier, reducing the risk of having too many sstables open.
-
A “promoted index” is the intra-partition index that allows seeking within a partition using the clustering key. Due to a quirk in the sstable index file format, this has to be held in memory when it is being created. As a result, huge partitions risk running out of memory. ScyllaDB will now automatically downscale the promoted index to protect itself from running out of memory.
-
Change Data Capture (CDC) tables are no longer removed when CDC is disabled, to allow the still-queued data to be drained. #10489
-
Until now, a deletion (tombstone) that hit data in memtable or cache did not remove the data from memtable or cache; instead both the data and the tombstone coexisted (with the data getting removed during reads or memtable flush). This was changed to eagerly apply tombstones to memtable/cache data. This reduces write amplification for delete-intensive workloads (including the internal Raft log). #652
-
Recently, repair was changed to complete one table before starting the next (instead of repairing by vnodes first). We now perform off-strategy compaction immediately after a table was completed. This reshapes the sstables received from different nodes and reduces the number of sstables in the node.
-
The Leveled Compaction Strategy was made less aggressive. #10583
-
Compaction now updates the compaction history table in the background, so if the compaction history table is slow, compaction throughput is not affected.
-
Memtable flushes will now be blocked if flushes generate sstables faster than compaction can clear them. This prevents running out of memory during reads. This reduces problems with frequent schema updates, as schema updates cause memtable flushes for the schema tables. #4116
-
A recent regression involving a lightweight transaction conditional on a list element was fixed. #10821
-
A race condition between the failure detector and gossip startup was fixed.
-
Node startup for large clusters was sped up in the common case where there are no nodes in the process of leaving the cluster.
-
An unnecessary copy was removed from the memtable/cache read path, leading to a nice speedup.
-
A Seastar update reduces the node-to-node RPC latency.
-
Internal materialized view reads incorrectly read static columns, confusing the following code and causing it to crash. This is now fixed. #10851
-
Staging sstables are used when materialized views need to be built after token range is moved to a different node, or after repair. They are now compacted regularly, helping control read and space amplification.
-
Dropping a keyspace while a repair is running used to kill the repair; now this is handled more gracefully.
-
A large amount of range tombstones in the cache could cause a reactor stall; this is now fixed.
-
Adding range tombstones to the cache or a memtable could cause quadratic complexity; this is also fixed.
-
Under certain rare and complicated conditions, memtables could miss a range tombstone. This could result in temporary data resurrection. This is now fixed. Fixes #10913 #10830
-
Previously, a schema update caused a flush of all memtables containing schema information (i.e. in the system_schema keyspace). This made schema updates (e.g. ALTER TABLE) quite slow. This was because we could not ensure that commitlog replay of the schema update would come before the commitlog replay of changes that depend on it. Now, however, we have a separate commitlog domain that can be replayed before regular data mutations, and so we no longer flush schema update mutations, speeding up schema updates considerably. #10897
-
Gossip convergence time in large clusters has been improved by disregarding frequently changing state that is not important to cluster topology - cache hit rate and view backlog statistics.
-
Reads and writes no longer use C++ exceptions to communicate timeouts. Since C++ exceptions are very slow, this reduces CPU consumption and allows an overloaded node to retain throughput for requests that do succeed (“goodput”).
-
Major compaction will now happen using the maintenance scheduling group (so its CPU and I/O consumption will be limited), and regular compaction of sstables created since it was started will be allowed. This will reduce read amplification while a major compaction is ongoing. #10961
-
The Seastar I/O scheduler was adjusted to allow higher latency on slower disks, in order to avoid a crash on startup or just slow throughput. #10927
-
ScyllaDB will now clean up the table directory skeleton when a table is dropped. #10896
-
The repair watchdog interval has been increased, to reduce false failures on large clusters.
-
ScyllaDB propagates cache hit rate information through gossip, to allow coordinators to send less traffic to newly started node. It will now spend less effort to do so on large clusters. #5971
-
Improvements to token calculation mean that large cluster bootstrap is much faster.
-
An automatically parallelized aggregation query now limits the number of token ranges it sends to a remote node in a single request, in order to reduce large allocations. #10725
-
Accidentally quadratic behavior when a large number of range tombstones is present in a partition has been fixed. #11211
-
Row cache will miss a row if upper bound of population range is evicted and has an adjacent dummy row #11239
{kind=link}
Operations
- Task Manager - a generic job tracker for long-running jobs. The Task Manager is a new per-node API that makes longlive internal tasks (such as repair or compaction) observable and controllable. Task Manager updates in 2023.1 are:
- The task manager will no longer run tasks that were aborted before being started.
- The task manager is now aware of repair-related tasks.
- The task manager now controls repair tasks with shard granularity.
- A crash in the task manager related to repair tasks has been fixed.
- Repair tasks can now be aborted via the task manager.
- Materialized Views: When auto-snapshot is enabled and a snapshot of a base table is taken, its views are now also snapshotted. #11612
- The removenode operation will reject streaming data from the leaving node. #11704
- It is now possible to replace a node by mentioning its host id, rather than its IP address. This is useful in container environments, where IP addresses are transient.
- A node checks if it was removed from the cluster before rejoining. #11355
- In the system.local system table, we now advertise broadcast_rpc_address rather than rpc_address, similar to system.peers and Cassandra 4.1. #11201
- Decommissioning a node is now rejected if some node is down, so that it’s possible to inform all nodes about the topology change. Similarly, bootstrap is rejected if there is a node in an unknown state. #11302
- Gossip no longer updates topology with the IP address of a removed node, during a replacenode operation, preventing a dead node from being resurrected. #11925
- The replacenode operation is used to replace a dead node. It has now changed to generate a new unique host ID rather than taking over the ID of the node it replaces. This makes the cluster more robust against cases where a node previously thought dead comes back alive.
Deployment and install
- If you are running with a multi data center deployment, check the Raft section above.
- Scylla Images (AMI, Docker, GCP IMage) are now using ubuntu-minimal, based on Ubuntu 22.04, instead of full Ubuntu.
- Ubuntu 18.04 EOL is April 2023. As such, ScyllaDB Enterprise 2021.1 does not support Ubuntu 18 install. If you are still using Ubuntu 18.04 and can not upgrade, please let us know.
- Some unneeded services are now disabled to improve security and reduce startup time scylla-machine-image#408
- The container (docker) image now uses the C locale 1 to reduce image size. Part of the ubuntu-minimal update.
- There are now two tar packages: the standard package now does not contain debug information, while a new package with the -unstripped suffix contains the debug information. This reduces download time.
- The .tar.gz package contents are now under a directory, similar to existing practice in most tarball packages. #8349
- The bundled Prometheus node_exporter package was upgraded to version 1.4.0. #11400
- The “snitch” is used to derive the node’s location (data center and rack). The AWS EC2 snitch now uses Instance Metadata Service V2 (IMDSv2) to access instance metadata, per AWS recommendations. #10490
- The installer no longer checks that systemd is installed if --without-systemd is provided. #11898
- The bundled Java driver was updated to version 3.11.2.4.
- The various cloud snitches, which determine the datacenter and rack association of a node, improved error checking of their communication with the cloud provider.
- The docker image is now more robust against different network conditions, which could cause it to fail to launch. #12011
- The docker image has received some fixes for regressions: the locale is now set correctly, the supervisord service name has been restored for compatibility with scylla-operator, and the service runs as root to avoid interfering with permissions outside the container. #10310 #10269 #10261
Security
- OpenSSL 3.0.9 (when available) to mitigate https://www.openssl.org/news/secadv/20230530.txt (medium severity)
- OpenSSL 3.0.8 (when available) released with vulnerability fixes #13744