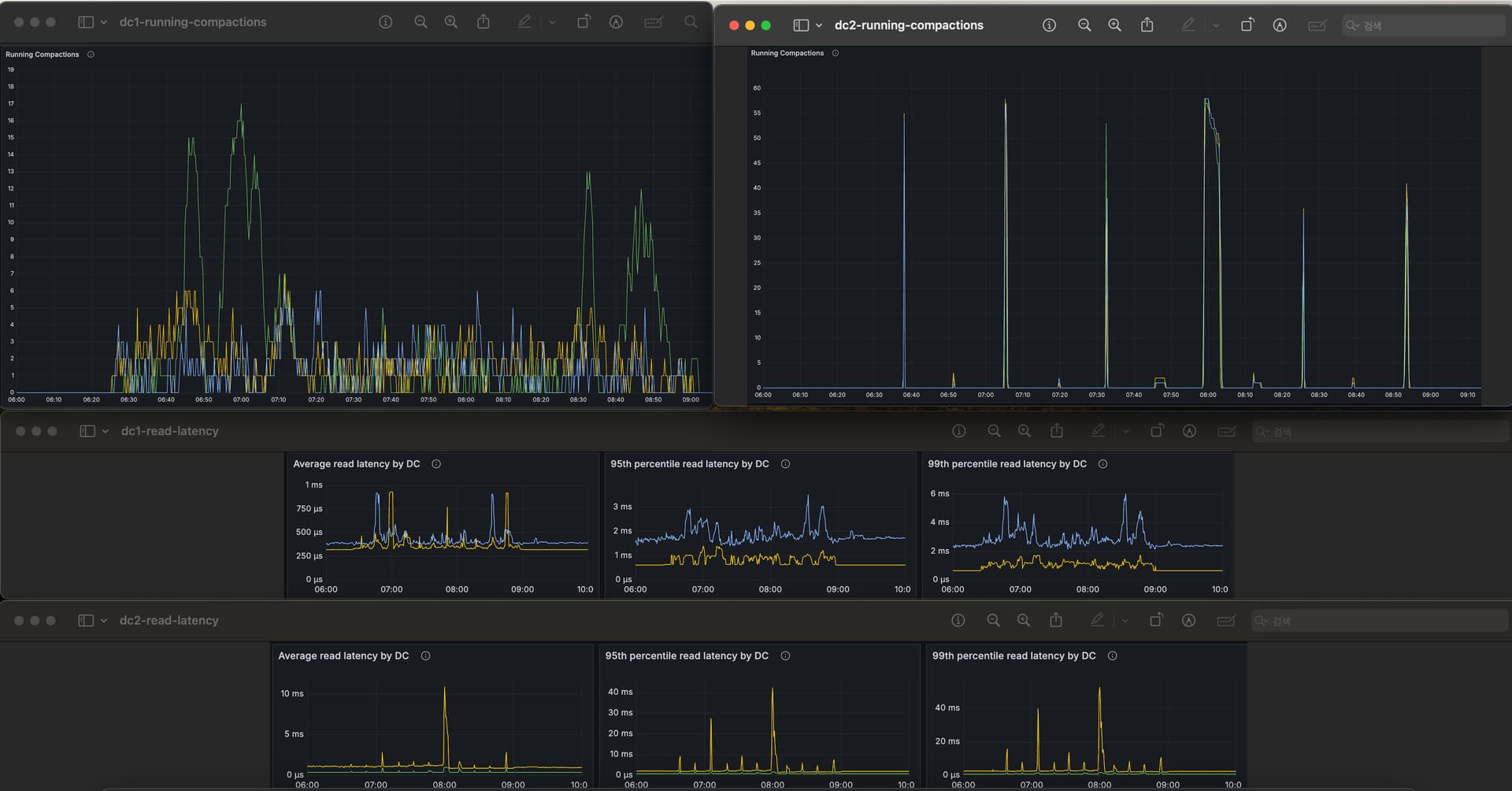
As daily batch job. we bulk write to DC1 using spark, and data are replicated to DC2.
While batch write is on going, running compactions occurs different in DC1 and DC2
While compaction occurs evenly in DC1, in DC2, compaction happens in large batches all at once.
I don’t know why compaction pattern is different.
And due to heavy compaction on DC2, durning batch operations, read p95, p99 latency spikes occur.
DC1 read latency has no problem.
I think DC1’s coordinator will relay to remote coordinator in DC2. So write pattern will be same. Therefore I think that compaction pattern should be same in DC1 and DC2.
But It shows different.
Is there anybody who knows why and how to reduce running compaction on DC2?
So if upgrade to Enterprise is an option, consider it and switch to ICS, it’s superior to STCS.
DC2 will recieve just one copy from DC1 coordinator and has to replicate it (to save bandwidth between DCs), this I think can create delays in how and when compactions happen in DC2. Also IO scheduler will impact this, so being on Scylla 5.4 or newer will also help. Older IO schedulers might not be that effective.
(or even better Enterprise 2024 will be just faster out of box, it has lots of improvements and optimizations and should be 30% faster than OSS)
Also if you are on latest Scylla and if disks/instance types are the same in both DCs you can try to decrease compaction_static_shares in scylla.yaml on all nodes in DC2 (which will make compactions run longer and be less aggressive to take resources away from queries) e.g. to 500? 300? or 200? this number is hard to tell without understanding the workload. If it’s write heavy and you want data compacted asap, then it should be higher.